英偉達對華“合規芭蕾”策略,國產算力加速“進化升級”
關鍵詞: 英偉達 芯片出口管制 合規經營 芯片較量 生態對決

7月16日,美國英偉達公司創始人兼首席執行官黃仁勛在第三屆鏈博會開幕式上致辭表示,“中國的開源人工智能是全球進步的催化劑,使每個國家和行業都有機會參與AI變革”。不久前,其在接受央視新聞采訪時宣布兩個重要進展,美國已批準H20芯片銷往中國,并同步推出了一款全新的、完全合規的中國特供版專業級RTX PRO GPU。
英偉達對華“合規芭蕾”經營策略
英偉達H20是專為符合美國特定出口管制要求而設計的A100/H100替代品。其核心性能,特別是FP64/FP32相較于A100/H100有顯著降低,但通過配備高帶寬HBM3顯存并保留強大的NVLink互聯能力,旨在維持在特定AI場景的競爭力。
今年4月,美國政府曾暫停向英偉達發放H20的出口許可證,導致公司面臨超百億美元的潛在損失。根據英偉達最新財年報告(截至2024年1月26日),中國市場為其貢獻了170億美元的營收,占總銷售額的13%,是其實現增長的關鍵支柱。
據報道,英偉達已重新提交H20的銷售申請,并獲得了美國政府將發放許可證的保證,公司期望能盡快啟動交付。
與此同時,英偉達CEO黃仁勛宣布推出全新的RTX PRO GPU。他將其定位為“智能工廠和物流領域數字孿生人工智能應用的理想選擇”。據臺媒《電子時報》披露,這款名為RTX PRO 6000D Blackwell的GPU將采用臺積電4N定制工藝,搭載GDDR7顯存,內存帶寬高達1.1TB/s。這一規格使其在處理復雜數據和高負載任務時具備卓越性能,尤其適用于企業AI部署和AI工作站。
然而,英偉達在滿足美國不斷調整的出口限制方面仍面臨挑戰。有消息稱,H20的替代版B30預計將于9月發售,其性能參數在現有基礎上可能進一步受限。傳聞其FP16算力約為80 TFLOPS出頭,FP8接近200 TFLOPS出頭,互連帶寬約為1.5–1.6TB。從整體性能看,B30被認為基本不適合用于AI模型訓練。相比之下,H20雖性能受限,但仍能通過優化內存方案、采用FP8精度及傳統方法勉強用于訓練。
事實上,英偉達的對華銷售策略已演變為一場精密的 “合規芭蕾”,通過分層產品線布局實現精準卡位。H20作為專注訓練及推理的定制芯片,憑借NVLink 4互聯與HBM3顯存支撐分布式計算;RTX PRO系列則聚焦專業可視化與輕量AI 設計,以GDDR7高帶寬適配數字孿生場景;即將推出的B30芯片則剝離訓練能力,純推理定位進一步收縮功能邊界。這種“功能切割術”既滿足美方不斷調整的出口限制條款,又通過差異化產品矩陣覆蓋中國市場從高端訓練到邊緣推理的全場景需求,牢牢守住13%的全球營收基本盤。
在技術綁定層面,英偉達即使硬件性能受限,仍可在軟件端通過CUDA工具鏈、NGC預訓練模型庫形成生態壁壘,僅PyTorch框架就包含超10萬款基于CUDA 優化的模型,開發者遷移成本高達百萬級代碼量;硬件端則與浪潮、聯想等中國服務器廠商深度定制聯合方案,將單芯片銷售轉化為“芯片 + 整機 + 服務”的捆綁模式,既規避單賣芯片的政策風險,又通過系統級合作深化用戶依賴。
芯片較量之外的生態對決
從行業發展的深層次看,美國政府也逐漸意識到,盡管對高端芯片實施出口管制,但中國在AI芯片領域的巨額投入正推動其加速填補算力缺口,寒武紀、壁仞等企業流片節奏提速,華為昇騰910B已進入多地智算中心采購清單,部分國產芯片在性能和應用層面已展現出與H20競爭的能力。
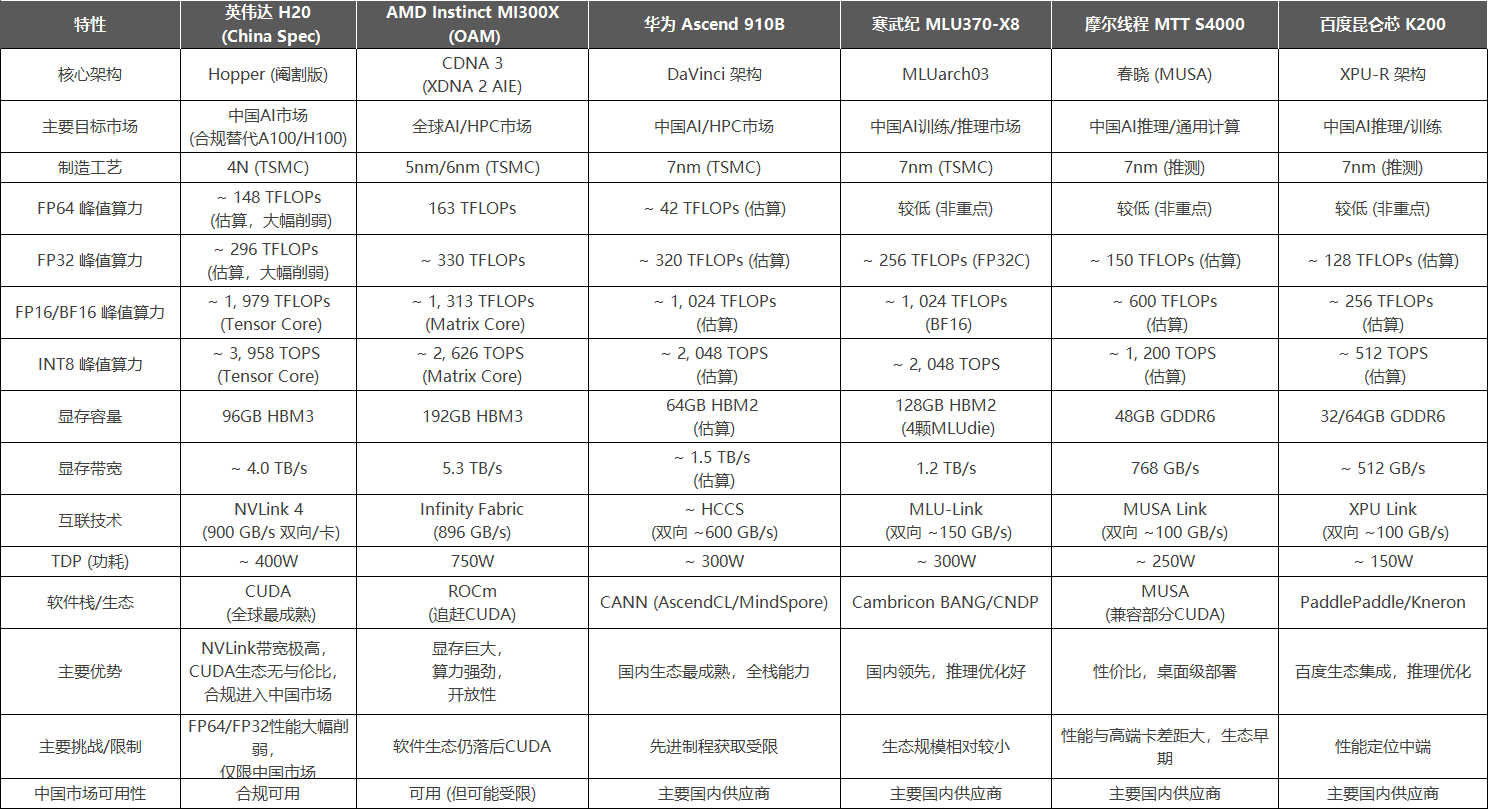
國外的相關GPU各有特點,H20作為特定地緣政治環境下的產物,最大優勢在于保留了NVLink 4的超高互聯帶寬和大容量HBM3顯存,這對于構建大規模AI集群進行分布式訓練和推理至關重要,能部分彌補其核心計算單元性能(FP64/FP32)被大幅削弱的劣勢,而CUDA 生態更是其護城河;AMD MI300X 紙面參數則非常亮眼,尤其是 192GB HBM3 顯存是巨大優勢,對處理大模型極其關鍵,不過 ROCm 生態是主要瓶頸,好在其正持續快速改善,同時該芯片功耗較高。
國內競品方面,華為昇騰910B 目前國內綜合實力最強的替代方案,擁有較高的FP32/FP16算力和較成熟的CANN軟件棧(與MindSpore深度集成),以及華為的端到端解決方案能力,然而受制程限制,其HBM帶寬相對國際旗艦有差距;寒武紀MLU370-X8 通過多芯粒集成實現高算力和大容量HBM2,在推理場景有較好表現和優化,但是MLU-Link互聯帶寬相對NVLink仍有較大差距;摩爾線程MTT S4000 / 百度昆侖芯 K200定位更偏向推理和中端訓練市場,性能參數上與H20/MI300X/910B等旗艦卡差距明顯,但在特定場景,如桌面級推理服務器、特定模型優化可能有成本和部署優勢,生態處于早期發展階段。
除了硬件參數,全球AI產業也深刻意識到,算力軟件生態的成熟度遠比單芯片參數更能決定技術落地的廣度和深度,對于正加速追趕的中國算力產業而言,突破軟件生態壁壘仍需攻堅三大關鍵節點。
首先,當國產芯片FP16算力達到320TFLOPS超越H20時,業界卻發現大量開源AI框架仍默認調用CUDA內核。這種硬件領先卻生態滯后的困境,折射出兼容性戰役的核心價值,國產芯片要打破“能用但不好用”的魔咒,必須構建跨架構適配層。而兼容性攻堅的終極目標不是復刻CUDA,而是構建“一次開發、多端部署”的跨架構生態。目前中科院計算所研發的“異構計算中間件”已支持昇騰、寒武紀、AMD等8類芯片架構。
其次,CUDA的真正壁壘,在于全球200萬開發者形成的創新網絡。國產生態要實現從“技術可用”到“開發者擁護”的跨越,需要建立可持續的開發者激勵機制。
最后,當美國商務部提出“讓中國對美國技術上癮”的策略時,國產算力生態更需警惕“表面兼容實則被卡脖子”的陷阱,真正的自主可控,體現在底層指令集到上層應用框架的全鏈條可控。
算力軟件生態的攻堅戰,本質是場沒有硝煙的標準制定權之爭。當國產芯片廠商不再糾結“如何兼容 CUDA”,而是思考“如何讓全球開發者主動適配國產生態”時,才算真正突破了算力產業的致命短板。這場戰役或許需要十年甚至更長時間,但每一行自主代碼的積累,都在為中國算力產業鋪設通往全球價值鏈頂端的階梯。